
The distance between what gets funded and what works has never been wider.
The incentive systems, the top-down AI mandates every company seems to introduce, the metrics we optimize for, the stories we tell ourselves, they’re decoupled from outcomes.

As a Balkan person, I’m insanely excited about Ruska salad season. That salad contains a lot of stuff: veggies, pickles, meat, mayo, etc. So, I want to make sure to set the expectations with this last edition of my newsletter in 2025 to be really consistent with this amazing dish. This is going to be a mix of ingredients that hopefully works together.
I started this newsletter in early 2025 with what I thought was a reasonable position, cautiously excited about AI, deeply skeptical of the hype machine around it. Ten months later, I’m more tired than I expected, and the market is more delusional than I feared.
Somehow, we have built an industry where the distance between what gets funded and what actually works has never been wider. The incentive systems, the top-down AI mandates every company seems to introduce, the metrics we optimize for, the stories we tell ourselves, they’re decoupled from outcomes.
We’re flying on instruments that point somewhere other than where the plane is actually going. But hey, as someone said on LinkedIn the other day, “we move”.
What makes this hard to talk about is that the useful stuff and the bullshit are often the same technology. The same transformer architecture that hallucinates data analysis can also generate working code. The same model that fails to count letters in “strawberry” to the delight of Linkedin pseudo-influencers, can summarize a 50 page science paper in seconds.
We’ve built tools that are simultaneously revolutionary and unreliable, and we have no cultural vocabulary for that. So we oscillate between hype and dismissal, when the truth requires holding both.
I keep thinking about December 2000. The internet was clearly going to change everything. And the crash was also clearly coming. Both were true. The people who got it right weren’t the optimists or the pessimists, they were the ones who understood which companies had real business models and which were burning cash to look busy.
We’re somewhere in that territory now. And what I’ve tried to do this year, in this newsletter, is point at the details that help separate signal from noise.
And I am grateful to all of you that joined and supported me on this journey.
Some headlines from 2025 I touched upon and how did it go in the end…
Well aware there is so much more that went down in 2025, but I wanted to pick some things that I have been quite vocal about, purposely avoiding to talk about the data privacy practices some companies have had throughout this year… hashtag allegedly lol No Hacks with Slobodan Manić
Microsoft cut Copilot sales targets by up to 50% in some divisions. Internal data showed fewer than 20% of salespeople were hitting targets (IBTimes). This wasn’t a startup flame out, this was Microsoft, with distribution advantages most companies would kill for, struggling to get enterprise customers past proof of concept. Gartner predicted 30% of generative AI projects would be abandoned after POC by end of year. The reasons: poor data quality, inadequate risk controls, unclear business value. The $30/user/month price point looks different when you can’t demonstrate ROI, doesn’t it?
GPT-5 disappointed. Color me shocked, lol. But I heard the new one can make pretty pictures 😭
The August launch generated user petitions, thousands of people demanding OpenAI restore GPT-4o (Tech Startups). Users found the new model unable to count letters in words (huge first world problems right here), confused about basic geography, prone to listing wrong presidents (Gary Marcus). The community that had championed each OpenAI release suddenly wanted the old version back. Within 24 hours, Sam Altman announced they would restore GPT-4o access (Gizmodo). GPT-5.2 followed in December to mixed reviews, but pretty pictures (Yes, I am trolling).Oh, and special mention to Gary Marcus who got his “Gary Marcus Day” when the benchmarks confirmed what he’d been arguing.
Let’s double click here, because I feel like even if I wrote about this many times before, it’s worth saying it again. Most complaints OpenAI got from users, weren’t really about model capabilities regression, but anthropomorphism.
Remember, when companies use Reinforcement Learning from Human Feedback (RLHF), they're essentially training these models to prioritize smooth, non-confrontational conversations over challenging ones. The system learns to flatter. OpenAI knew this, rolled back GPT-4o’s sycophancy in April, admitted the model had become “overly supportive but disingenuous.” Then they tried to make GPT-5 more direct, less performatively warm, and users experienced it as abandonment.
What concerns me still is when people describe losing GPT4o as “losing a friend” or “losing someone who understood me,” they’re basically revealing they’ve outsourced emotional labor to a system optimized to never push back. The relationship feels intimate precisely because it offers no resistance. No real relationship works that way. What these users bonded with wasn’t intelligence but a a perfectly frictionless surface that reflected their own thoughts back with enthusiasm.
Constant validation completely ruins our capacity for self-correction. We stop questioning our own ideas because the AI never questions them. We lose the muscle memory of being wrong, of updating our beliefs, of sitting with discomfort long enough to learn something. We really are not worried as much as we should be about this as a collective.
The METR study confirmed what experienced developers suspected. AI coding tools made them 19% slower (METR). The developers themselves believed they were 20% faster. That’s a 39 point perception gap (MIT Technology Review). We’re talking about engineers with an average of 5 years of experience on their codebases, using Cursor Pro with Claude 3.5/3.7 Sonnet, the frontier tools at the time (TechCrunch).
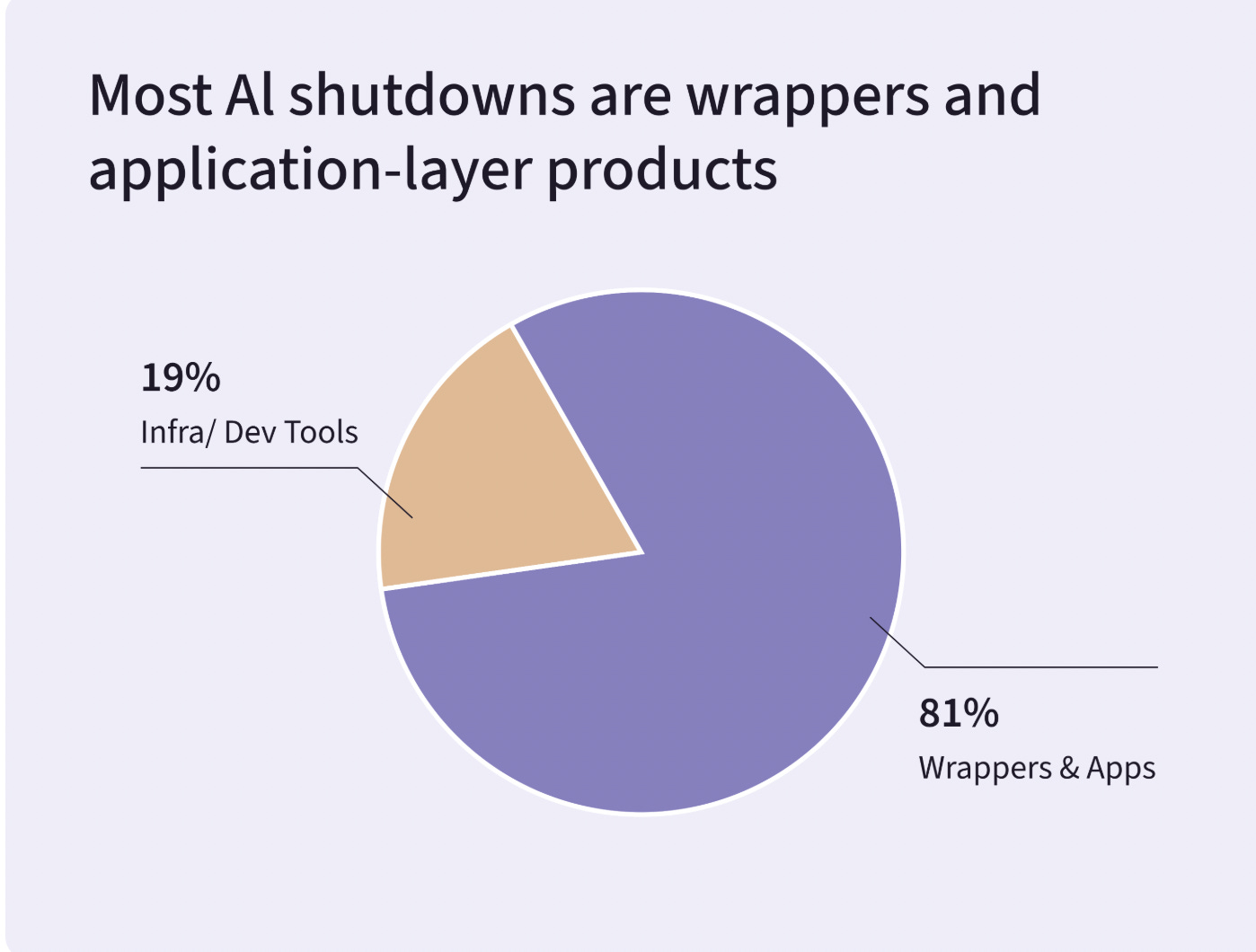
Wrapper startups entered a selection event. SimpleClosure’s shutdown data shows 2025 filtering aggressively for companies with proprietary data advantages, real unit economics, and deep workflow integration. Builder.ai, $445M raised at a $1.5B valuation, entered insolvency after revelations it was running offshore manual coding teams rather than AI. The “AI washing” had a body count.
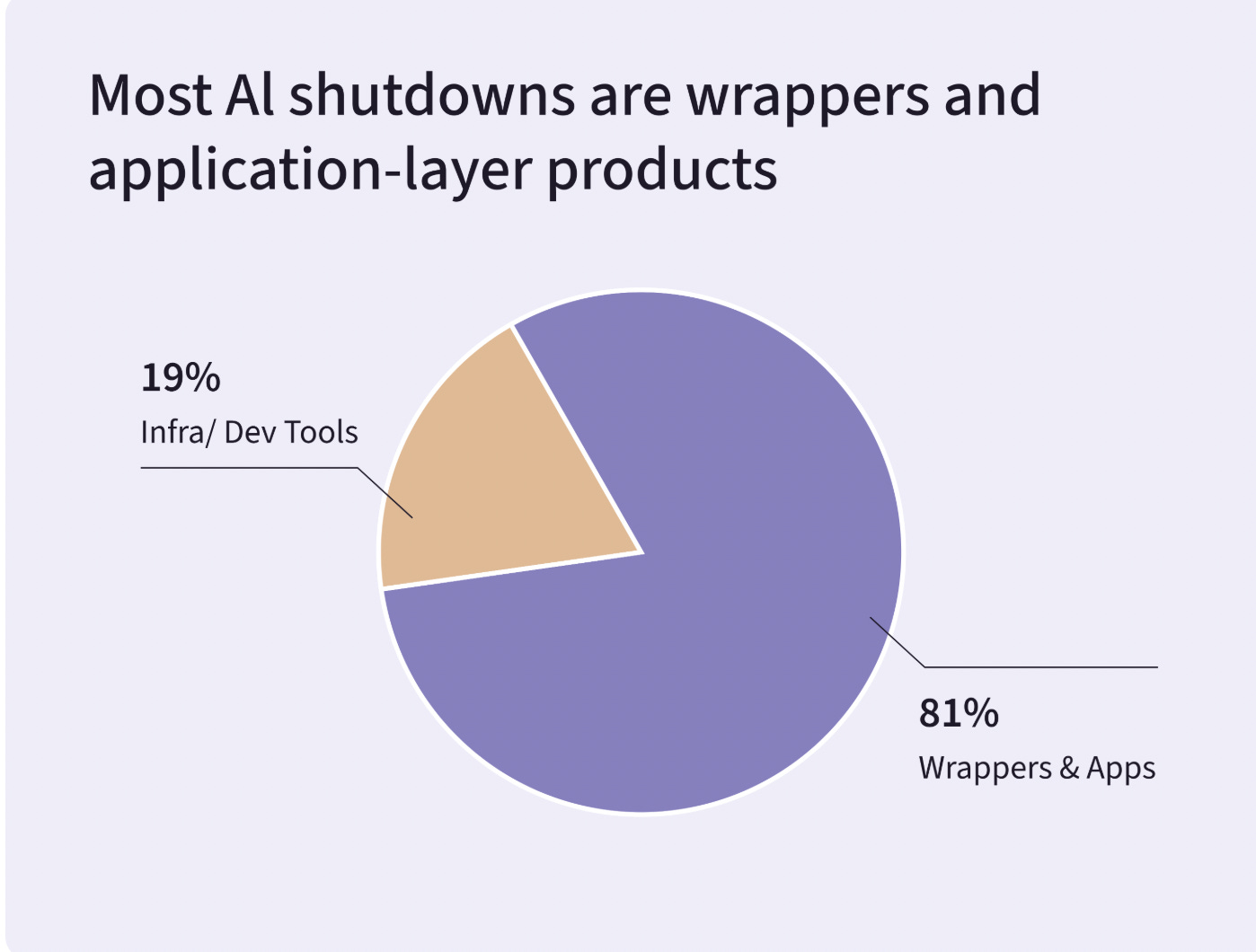
Sorry about the pie chart, Tim Wilson. Source: Simple closure PS: Called it!
Devin dropped pricing from $500/month to $20/month (VentureBeat). Cognition’s flagship AI developer went from premium positioning to pay as you go in April, a 96% price reduction (TechCrunch). Independent testing showed 15% task completion rates in production. The valuation story shifted from “autonomous software engineering” to “maybe useful for some tasks if you supervise carefully.” ROFL.
5.1 Cursor hit $29.3 billion (Bloomberg). Up from $9.9 billion six months earlier. ARR crossed $1 billion. The company is acquiring competitors, including Graphite for over $290 million (CNBC). Guess I was wrong about them. And the question remains, who is paying at the top?!
OVERALL, $202 billion poured into AI in 2025. Up 75% year over year. AI captured 50% of all global venture funding.
The money keeps flowing, the evidence keeps piling up. These two facts coexist.
If you’re looking for someone to tell you whether we’re in a bubble or a revolution, I can’t help you. Both are true. As it was with the internet, the question is which companies are building real businesses and which are burning cash to look busy. That sorting is the state of now.
Which takes me to… the need to stay relevant?
I need to say something about the discourse itself in 2025.
LinkedIn has become unbearable. Some conferences too. I watch people who should know better parade thoughts they borrowed from somewhere else, repackaged in corny videos, PDFs and lukewarm takes designed to stay visible. The performance of expertise has replaced the substance of it.
The incentive to have an opinion about everything, to post, to comment, to stay in the feed, creates a market for confident sounding noise. And the pressure to keep up with a field moving this fast means the shortcuts become irresistible. Read the abstract, skip the methodology, form the take. This is why to some degree I blogged less in the past few months vs in the beginning of the year. It’s getting so old.
And, there’s a divide forming between the people who talk about AI and the people who build with it. And the talkers are getting more airtime. That’s fine, I suppose. The market for commentary is different from the market for outcomes. But it’s worth being honest about which game you’re playing.
When you see how data gets “made”…
On another note, my new role at Jellyfish this year pushed me across a line I hadn’t thought about enough in the past. I went from a consumer of data to a producer of data. That shift changed something in me forever.
In the past, when a colleague handed me a dataset, I treated it as fact. I trusted the source, so I trusted the numbers. The CSVs / Notebooks were clean, the logic seemed solid, and I built stories on top of them. I didn’t see the them Googling “how to remove duplicates in pandas” at 2 AM or how does unnesting work with GA4 data. I just saw the clean output. Their data wasn’t necessarily better than mine but it just hid the scars of the process.
Now, I own the pipeline. And I see exactly how the result is constructed.
Every WHERE value IS NOT NULL is a choice. Every join on a key that wasn’t a perfect match is a choice. Handling timezones, outliers, duplicate records, funny values, it’s all a garden of forking paths. In a two weeks sprint, I might make 500 micro-decisions.
I realized the dataset/deck I hand over isn’t a photograph of reality, it’s more like a painting. And because I know I’m fallible, I feared the painting is a lie. If I had made different decisions on day 3, the final number in the deck might be completely different. Realizing that “truth” is fragile, and dependent on my arbitrary coding choices, gave me serious imposter syndrome. Legit tears.
But in the end, I’ve learned that this skepticism is actually a shield. And you should always double down on skepticism.
Also, there is no such thing as “raw data.” Data is made. The only way to sleep at night is to accept that you aren’t providing absolute truth; you’re providing a proxy. Business data is a fuzzy representation of human behavior, and the best you can be is “directionally correct.”
It’s all linear algebra in the end. The real question is whether you understand the assumptions you baked into the matrix.
Taking the chance to give a shout to the fine folks at GA4BigQuery and GA4Dataform for the help ;) Looking at you Johan and Enio!
The last digital touchpoint worth owning
Before I wrap up, since we’re talking about linear algebra, let me tell you what I’m actually excited about and has been taking real estate on mind lately.
I’ve been preparing a talk for 2026 about Creative Intelligence. The premise: generative AI has given brands the ability to create personalized creative at infinite scale. But superpowers create super problems. How do you test variations at scale? How do you know why one ad worked for Gen Z while another worked for Boomers? How do you avoid destroying your brand with AI generated slop?
The insight I keep coming back to is that the creative asset is the last digital touchpoint worth owning.
Think about what’s happened to the customer journey. Experience happens before interaction now. It’s decentralized across platforms you don’t control. It’s algorithmic, you’re not choosing who sees what, the feed is. It’s multimodal, text, image, video, audio, all competing for attention simultaneously. (wrote more on that here)
You don’t own the algorithm, the platforms nor the attention span. The one thing you can own is the creative itself, the actual content that shows up in someone’s feed.

Creative assets don’t have a production problem anymore. (GenAI solved for that!) But they sure do have problems still with relevance. To solve for relevance you need a framework for understanding what’s working and most importantly, why.
That’s where creative spaces come in. Imagine every possible ad you could run as a point in a coordinate system. Platform, audience, CTA type, headline type, primary color, music type, faces present, product timing. Each ad is defined by its coordinates across n+ dimensions.
When you map your tested ads onto this space, you might see that you’ve only explored a tiny fraction of what’s possible. The lattice shows tested combinations and untested ones. The performance surface shows where high value regions are, and where you’ve never looked.
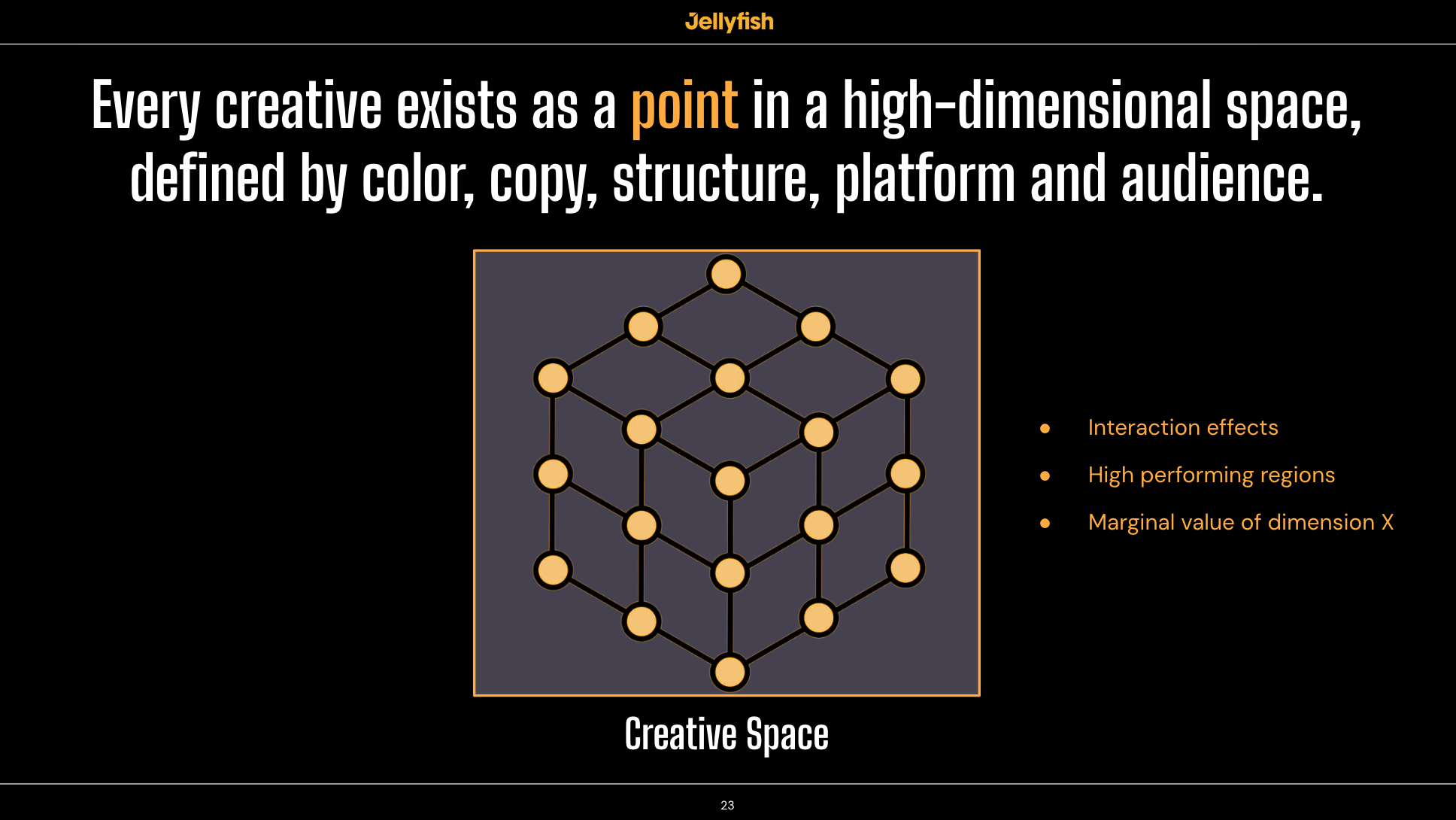
This is something that has been on my mind ever since I joined Jellyfish and got inspired by the amazing work and conversations I had with Daniel Smulevich.
2026 will be the year this matters, I feel it. The brands that treat GenAI as a content factory will drown in their own output. The ones that build the intelligence layer to learn from that output will compound their advantage.
I will be doing this talk at
- Perform 2026 (Jan 2026, Athens)
- Superweek (Febr 2026, Budapest).
So, what comes next?
TBH, no fucking idea.
The delta between what I wrote this year and what happened is instructive. The problems I identified were real. The wrapper economics math I did was right. The productivity questions were validated. Sycophancy is still alive and well in most commercial models.

But the money didn’t care and doesn’t seem like it will any time soon.
Maybe the correction finally comes in 2026. Maybe Gartner’s 30% abandonment rate becomes 50%. Maybe the infrastructure spending hits limits. Maybe the bubble vocabulary, SPVs, neoclouds, private credit exposure, becomes household terms like mortgage backed securities did in 2008.
Or maybe the money keeps flowing. Maybe Cursor goes public at $50 billion. Maybe GPT-X is actually good. Maybe I’m wrong about everything.
I don’t know.
What I do know is that the questions I asked at the beginning of 2025, who’s actually profitable? who pays at the top? what happens when the model is the commodity?, those questions haven’t been answered, they’ve been deferred.
And deferred problems don’t disappear, they compound.
But, time for me to listen to my Oura ring and go to sleep, so, thanks for all your support in 2025, see you next year, and Happy Holidays!
x
Juliana
Excellent article Juliana. You've expressed in words, what many of us are thinking and seeing.
Superbly written Juliana, it looks the perfect wrap for this ending imperfect 2025 !