
The funnel is dead. Long live the creative asset.
We need to stop solving 2026 problems with mental models from 1898.

On my mind this week month months
2026 started with me going in a food coma after Xmas, intellectual coma because I’ve been obsessing over response surface methodology and factorial ANOVA and how to decompose creative assets and measure their performance (we will talk about that in this newsletter, yay) … and a bit of travel coma because, it’s the last day of January and I’ve already been to 3 countries, 3 stages and mixed that with a shitload of work, flu and constant alerts from my Oura ring for my “body strains” lol
HOWEVER, it was worth it, and good for sure, I always love to go back to Athens, what a lovely audience!, and just this week I had the chance to speak for the first time at Bhav’s event in London, CRAP Talks.
Finally, many thanks to the speakers and attendees of the very first Jellyfish x Google Cloud Talks event we organized in Copenhagen. Couldn’t have asked for a better turn out. So grateful to you all.

And, yes, next week is SUPERWEEK time, and I’m already getting warm and fuzzy inside because besides being a speaker this year, I get to see some people I have a lot of love for in real life (cough cough Matt, Tim, Jason, Fred and many others)
Finding the next big problem
OK, so the last time I felt so strongly about doing a project that requires a bit of a unconventional, maybe alternative thinking was when I started working with Krasi on semantic analysis back when we were both at Monks and working on Starbucks.
That project ended up being the most important and popular one for both of our careers, and helped us win 4 industry awards in 2025, which btw, I still cannot believe.
We used NLP and specialized language models to solve a problem that standard tools couldn’t touch back then. But now, everyone has an agent for text analysis. We solved the text problem. And, as I moved on with my career to a tech first agency, I realized we were facing a much bigger, more interesting problem: the visual one.
So, in this context, it didn’t take me long to start asking myself deeper, more exciting questions:
What will the future of measurement be like? And is there something for us to measure still, since most of the digital marketing/digital experience world has moved on from linearity to… chaos?
The answer starts with admitting that we’re still trying to solve 2026 problems with mental models from 1898.
Elias St. Elmo Lewis gave us the purchase funnel (Awareness, Interest, Desire, Action) over a century ago. It was a model predicated on linear control. Every SaaS or agency on the planet that worked in digital marketing created some sort of version of it and we used it all for measurement because frankly, that’s all we had.
But the modern customer journey is chaotic, fragmented, and multimodal. It loops through TikTok feeds, Reddit threads, and YouTube comparisons in sequences no brand can orchestrate.

In this environment, the idea of “meeting the customer where they are” has become a platitude. The reality is that we have lost control of the context. We cannot control the platform algorithm, the competitor’s bid, or the user’s headspace.
There is only one variable that actually travels with the customer across these fragmented touchpoints is the creative asset itself.
Your attribution model doesn’t always survive the jump from Instagram to the web searches, your targeting strategy doesn’t always persist. But the content, the video, the copy, the offer is the only thing that still does.
This means the asset must now carry the entire strategic load. It is no longer just an ad; it is your storefront, your brand identity, and your closer, all compressed into a single point in a high-dimensional space.
And here is where I found my next big problem: we are measuring this all-important variable with tools that are fundamentally broken.
The Haystack Paradox
For 30+ years, since The One to One Future: Building Relationships One Customer at a Time book was released, we have been saying as an industry that the bottleneck for personalization and relevance was production. We couldn’t create enough assets to match the fragmentation of the market, then the internet’s.
Then, GenAI came to be and just in a few years, the production constraint vanished. We can now generate thousands of variations of creative concepts before lunch. You just need to know how to prompt and understand image/video params and dimensions when you do so.


But in our hype for this GenAI “efficiency”, we might have missed on the realisation that we have replaced a scarcity problem with a noise problem.
We built a massive haystack of content, but we are using measurement frameworks from 2015 to find the needle. This is what I call, the haystack paradox. The more creative assets you generate, the harder it becomes to identify what actually works .
Let’s define what a creative asset is before you understand how unforgiving the math is here.

Ad #437 is a specific point defined by [blue + Free Shipping + 2.5sec timing + Shop Now + TikTok + Gen Z].
We’re used to think of ads and assets as indivisible units, ‘Ad A’ vs ‘Ad B.’
In fact, every ad /asset is actually a bundle of choices across multiple dimensions aka variables… or components.
So, if you want to test just a basic matrix: 5 background colors, 5 headlines, 3 CTA types, and two timing variations across three platforms and four audiences, you are looking at maybe 1,800 possible combinations . Add music, face presence, and copy length, and you can quickly exceed 40k variations.
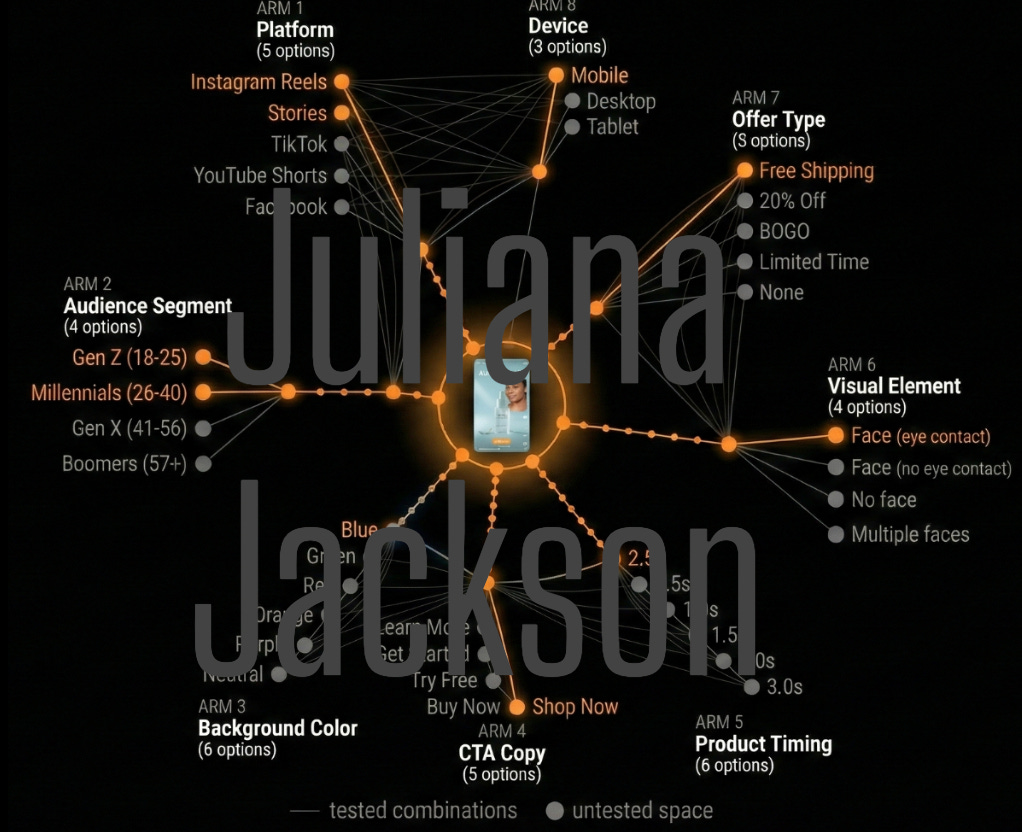
Sure, GenAI makes building these 40k assets trivial. But testing them via traditional A/B testing is mathematically impossible. You simply cannot run 40K split tests, the budget and time simply do not exist.
Component Blindness
So, why does traditional testing fail here? Sure, you can run some MAB (multi-armed bandits) but they are only good to tell you which ad won, not why, they are only good at finding what is the local optima, they cannot map a creative space.

Traditional testing treats the creative asset as an indivisible, atomic unit. We test “Creative A” against “Creative B,” declare a winner, and move on.
This creates component blindness. When “Creative A” wins, you have no idea why. Was it the pacing? The headline? The specific interaction between the music and the audience segment?
So, because we treat the asset as a black box, we learn nothing transferable. We burn budget to rediscover the same insights in every campaign, resetting our intelligence to zero each time.
In reality, a creative asset is a bundle of strategic choices, a coordinate in a multidimensional space defined by variables like color, copy, timing, and structure .
So here is when it hit me, to solve this “haystack paradox” we have to stop testing for “winners” and start mapping the creative space.
What the hell is a creative space?
There are many ways to look at it, but my take is that a creative space synthesizes past campaign performance, taxonomies, brand guidelines, tone of voice, messaging, and various other creative assets variables and dimensions.
This data can be then used to predict future performance of creative assets.
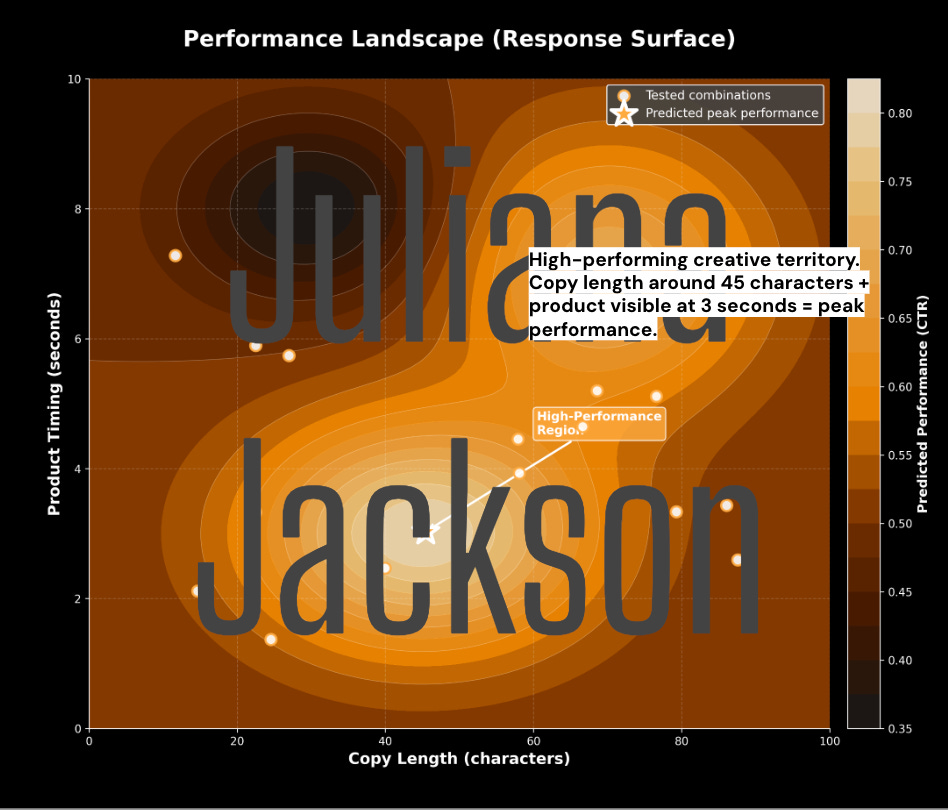
This is where I’ve been burying my head in Response Surface Methodology (thanks Matt). A creative space isn’t something random, it has a topology.

The variance in performance comes primarily from two sources:
Main Effects (First-Order): The individual impact of a single element. For example, a blue background might drive a 12% lift on its own .
Interaction Effects (Second-Order): The combined effect of two elements working together. A blue background might generally perform well, but when paired with a “Shop Now” CTA, it generates a 25% lift, an outcome greater than the sum of its parts. Also, could be that same blue background might tank performance when paired with a “Learn More” CTA.
So, if creative quality drives 50–60% of sales performance (which Nielsen, Kantar, and Meta data suggests it does) that variance lives in these interactions.
We don’t need to test every straw in the haystack (i.e all 40k combinations). We need to use principles of experimental design to test a strategically selected subset, perhaps 200 coordinates.
Then, by analyzing the performance of these anchor points, we can map the response surface of the creative space. We can identify the high-performing clusters and accurately predict the performance of the thousands of combinations we never actually launched.
So, what is Creative Intelligence and why does it matter to me, to you and anyone?
Because for ages we have treated creative production as an expense, a disposable cost necessary to feed the algorithm. We make ads, we run them, they fatigue, we throw them away.
Creative Intelligence is the ability to map the topology of your creative space to predict performance, engineer relevance, and build compounding organizational memory. (what CRO folk call a culture of experimentation)
When you shift to Creative Intelligence, you change the unit economics of your marketing.
By mapping the topology, you can predict low-performing quadrants before you launch. This allows you to kill the 55% of assets that typically waste budget during the learning phase. You are no longer paying media dollars to find out an ad is bad; you are filtering it out in the “Pre-flight” stage based on predictive scoring.
You cannot control the algorithm, the audience, or the platform, the creative asset is the only lever left. By understanding the mathematical structure of your creative, you stop gambling on the platform’s black box and start engineering your own relevance.
Most brands hit reset on their intelligence with every new campaign. They start from zero. But when you map the space, your knowledge compounds. Campaign 10 is smarter than Campaign 1 because it is built on the structural learnings of the previous nine. You are building an organizational memory that your competitors, who are still randomly A/B testing, cannot replicate.
This shifts the thinking from Creative Optimization (finding a local optima for this week’s campaign) to Creative Intelligence (building a global map of what works).
We are moving toward a framework where we validate assets before they launch (”Pre-flight”), diagnose components in real-time (”In-flight”), and build organizational memory that compounds (”Post-flight”).

I am going to leave you on cliffhanger for now, but I will be back with more soon.
And if you are at Superweek next week, you will get the full story from me. Also, if this is something of interest to you or your company, feel free to reach out to me by replying to this email.
Mentions
Thank you Daniel, Matt, Tim, Jason, David, Myles, Shiva, Eddie, Craig, Fredric for your feedback and support on this project and for humouring me :)
Thank you to everyone subscribed to this newsletter, I really love coming here every month and sharing my thoughts with you all. I am so glad you find these musings useful.
Updates:
If you are following my podcast - Standard Deviation, the first episode of Season 5 has aired yesterday with non other than Sayf Sharif. Check it out here.
Simmer just launched a new course: Data Analysis with R - taught by Arben Kqiku for which they have an active discount running. Stats are totally coming back in 2026.
Jason Packer’s book is out - Google Analytics Alternatives: A Guide to Navigating the World of Options Beyond Google - you can get it here. I know I did!
Last ticket release for Measurecamp Helsinki is happening 10th of February 1PM EET (12PM CET) - last chance to get a ticket to the best Measurecamp.
Finally, Experimentation Elite Space Academy is happening on the 7th of May, and the focus is Data Science & AI in experimentation. I am hosting the event and I will be dressed up as Darth Vader the whole day because it has a space theme. SO MUCH MILLENNIAL PEAK GOAL. Check it out here.
Until next time,
x
Juliana
This was such an interesting read! Brava Juliana! I am jealous of your brain!
This is so interesting and so mind 🤯at the same time. Have definitely been left on a cliff hanger 🤣. Brilliant read ❣️ Juliana!