
Large Language Models Can't Handle ALL Your Data Problems.
If your entire data pipeline is one prompt, the model isn’t your biggest problem.

On my mind this week
My first real meeting with data science was a hacky sentiment analysis pipeline made out of Apps Script, a Google Sheet, and the GCP NLP API, an experiment I tried immediately after hearing and seeing Milly KC describe the process on a podcast we recorded together with Mike Robins in 2022! GOD, it’s been a minute.
Months later I ended up working at Monks where I met my dear friend and colleague, Krasimir Bambalov, who walked me through F1 scores, linear regression, topic classification, anomaly detection, predictive models and so much more.
That pushed me to work very hard to learn foundational machine learning, deep learning, and statistics. And I managed to learn so fast that I was an integral part of the small language models and LLMs powered products we’ve built together. While I do not write the code, I can move from feature specs to edge case debugging without losing the plot. I can hold my own haha.
So, specifically because I respect and love this craft so much, and since this has been my world since, I wince every time someone says “AI is terrible at data analysis”
Besides that being an absolutely PARADOXICAL statement, 9 times out of 10 what people really mean is “I dumped 4 CSVs into GPT/Gemini/Claude, asked for insights, and got nonsense.”
NO SHIT.
Text Prediction ≠ Data Analysis
Let’s take this step by step.
Remember transformers? we covered them in the previous edition, they encode numbers as pieces of text, carry a fixed context window, and sample probabilistically. They have no native routines for cross validation, no inductive bias for tables, and limited ability to scan large matrices accurately.
In contrast, models like gradient boosted trees or linear models are specifically built for these kinds of tasks (don’t worry, I am covering them below). They can quickly analyze large amounts of data, give you consistent results, and they come with clear ways to measure their performance.
If you need accuracy, confidence, speed with large datasets, or reliable statistical insights, these other models are much better suited for the job than a model that was never built to work with numbers and tabular tasks… aka a language model.
So why do teams keep pushing spreadsheets through chat boxes? WELL…
One prompt feels faster than writing a Pandas pipeline.
Everything now lives in a chat interface, so every task gets framed as a chat query. Thanks Open AI.
A few impressive reasoning demos created the belief that LLMs do everything well.
Also, the biggest issue is that people talk about AI without really understanding what it really is or how it works. The best, and worst, thing about LLMs and easy access to APIs is the same: anyone can glue Google Sheets to GPT with a quick Apps Script, pump out LinkedIn posts, auto-summarize reviews, and run “sentiment analysis” with zero precision/recall checks. That’s how I started out too! BUT, "the magic" of abstraction hides the fact that most users have no idea how the model, or real data science, actually works.
You need to do the work. You need to learn and properly understand the mechanics of AI before you go further than demonstrative / quick POC use cases.
As Richard Feynman famously said, just because you know the name of something doesn't mean you know that something.
Beyond The Mean
Let’s address the conflation in the room…with science.
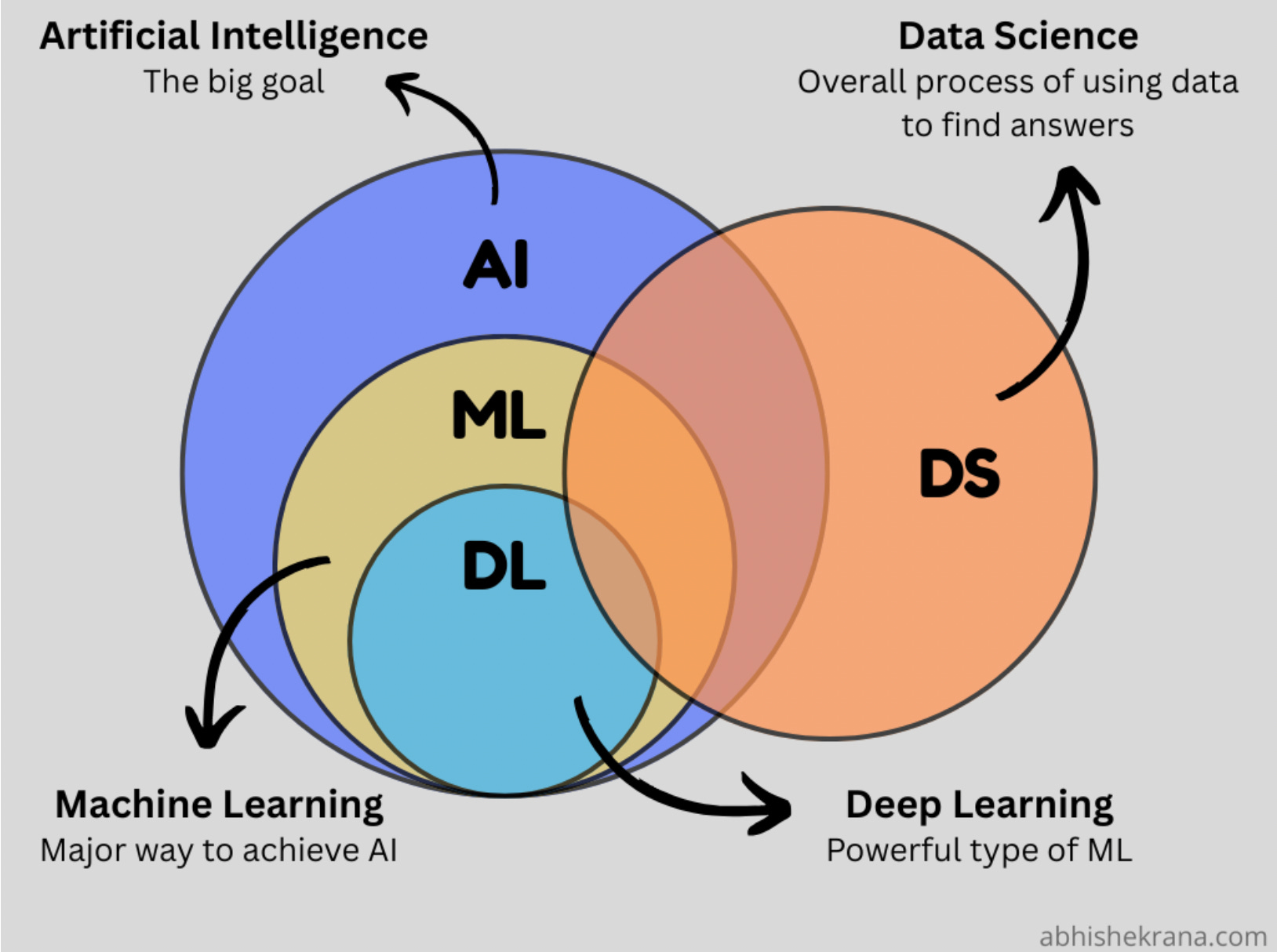
AI is simply put human intelligence exhibited by machines. That's the big goal. To get there, we use all sorts of methods: classical machine learning, deep learning, tree ensembles, graph networks, Support Vector Machines and so on. Then you've got language models built to generate text, images, videos. Others designed to parse tables and structured data.
All these things work completely differently. Tree ensembles? Nothing like neural networks. SVMs? Totally different principles than transformers. Language models and table parsers are solving different problems with separate methodologies entirely.
But somehow all of it gets lumped under the same 2 letters: AI.
Like it's all interchangeable and it all works the same way.
So when someone throws structured data (tables) at GPT and gets garbage, the model gets blamed. But the real problem is that they picked the wrong class of model from the start.
In the end, data analysis is more than parsing numbers, it’s statistical reasoning. That requires algorithms with built in assumptions about structure, distribution, and noise. Language models simply don’t have those.
Not to mention all the effort that goes into collecting, cleaning and normalizing that data before you even get to analyze it.
LLMs are trained to generate sequences of text based on probability. That makes them good at language tasks like summarization, translation, Q&A. But statistical tasks require a very different setup:
Tabular models like XGBoost are designed with inductive biases meaning they have built-in assumptions or "hunches" about the kind of patterns they expect to find for structured data. They inherently expect rows, columns, and relationships between features.
Linear regression assumes linear relationships and gives you coefficients with interpretable meaning, standard errors, and confidence intervals. You can test hypotheses. You can evaluate assumptions (normality, independence). Try getting any of that from a raw GPT output. (thanks Stanford course)
Neural networks built for structured data, like TabNet or specialized feedforward nets use attention or feature sparsity controls tailored for numeric inputs. They optimize directly over ground truth (the target for training or validating the model with a labeled dataset) and can handle large datasets efficiently when tuned properly.
Statistical analysis iis always more than getting the “right” number. It’s understanding uncertainty, testing significance, accounting for bias, and validating results against known baselines. And that requires pipelines…not prompts…
If it’s one thing I want you to take away from this ranty newsletter is that LLMs don’t fit distributions and they don’t validate assumptions. They guess plausible text, which might look analytical, but it’s NOT grounded in the math that matters. (I explained this more in depth here)
So, if your goal is rigor, repeatability, and decisions you can defend, then you need models built for statistical reasoning not text completion, otherwise, you’re just watching a model simulate the shape of analysis and hoping it gets close enough to truth to pass as insight.
To understand these nuances better, I’ve spent some time going into the latest research I could find about LLMs and their performance on numeric and tabular tasks… and wanted to share with you.. that things haven’t changed much.
Let’s see:
Hegselmann et al. (2023) – TabLLM: Few-Shot Classification of Tabular Data with Large Language Models
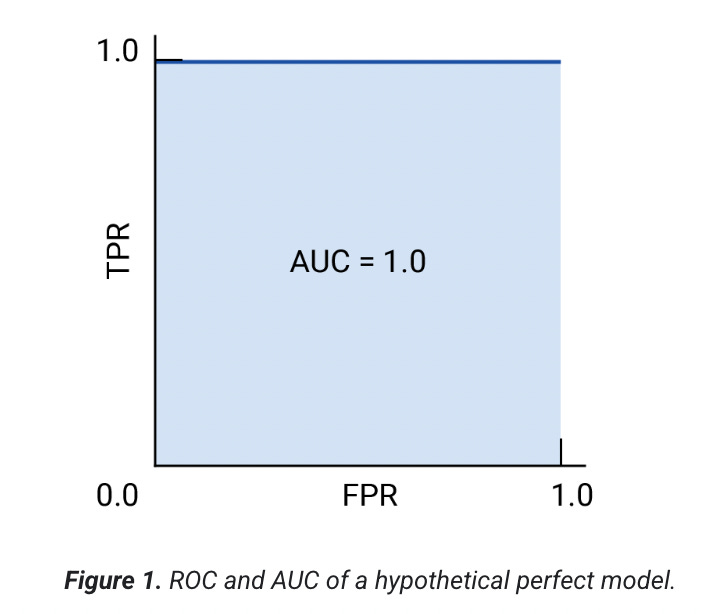
The test wanted to determine if a text-based model classifies table rows with virtually no labeled examples. On their income dataset (48 000 rows), TabLLM scored 0.84 AUC (means area under the ROC curve - had to look it up myself - and it measures ranking quality: 1.0 is perfect, 0.5 is random) versus 0.50 for XGBoost (a gradient-boosted decision tree model, that I explained above).
With almost zero labels, an LLM’s pretrained knowledge can flip the usual performance gap, though it still misunderstands raw numeric features without fine-tuning.
This means that in some scenarios a LLM can come in handy where there is not much data for analysis and their prior knowledge can compensate for that of lack of data.
Jayawardhana et al. (2025) – Transformers Boost the Performance of Decision Trees on Tabular Data across Sample Sizes
They tested models like GPT3/FlanT5 versus XGBoost across 16 public datasets ranging from 10 rows to 50 000 rows.
In the few sample regime (AKA TINY DATASET available for finetuning), the LLMs ran about +10% higher in plain accuracy (percent correct); but once you reach thousands of rows, XGBoost regains the lead. So the classic method > LLM.
Like in the previous paper, LLMs’ strong priors help on tiny datasets, but their fixed context windows and lack of inductive bias for tables make them extremely uncompetitive at scale.
Tian et al. (2024) – SpreadsheetLLM: Encoding Spreadsheets for Large Language Models
They wanted to prove whether augmenting GPT4 with chain of thought prompting and light finetuning to answer questions over multiple spreadsheet tables (307 questions across 64 sheets) can lead to better results in terms of tabular tasks.
They achieved 74.3% accuracy versus 62.2% for prior table-QA systems.
That basically means that breaking down reasoning into explicit steps and minimal task specific tuning lets an LLM overcome context length truncation and outperform specialized spreadsheet engines.
I’ve also recently tested this to some degree at work. When I wrote a prompt for a specific use case we had, I made sure to force the model to provide a “root cause” for the way it classified some textual data. This also helped me verify the results faster because it was quite hilarious that even if the LLM misclassified, the confidence it had in the root cause was out of this world lol.
Chegini et al. (2025) – RePanda: Pandas-Powered Tabular Verification and Reasoning
Ok, so in this paper they tested a specific LLM that executes Pandas code under the hood on fact checking benchmarks (TabFact and WikiFact great datasets to play with btw).
RePanda reached 84.1 % accuracy on TabFact and 84.7% on WikiFact versus aprox 80% for transformer only baselines aka LLMs.
And indeed, offloading actual data operations to a code engine fixes hallucinations and bad reasoning, producing good verifiable results. But nothing an LLM can do on its own.
But wait, Juliana, didn’t you say accuracy is the devil?

Yes, I did but In these benchmarks, classes or answers are roughly balanced, so overall percent correct does reflect performance. Metrics like F1 or precision/recall that I always talk about become critical only when label distributions are skewed or error type costs differ significantly. (Thanks Krasi for explaining that to me some time ago, I finally get it now)
And the main takeaway from all this research I linked above (that I did not cherry pick, so don’t @ me lol) is that language models bring strong priors when data is scarce or tasks demand flexible reasoning, but vanilla text only approaches fall short on big, numeric heavy datasets and precise arithmetics.
In those cases, you need to turn to dedicated numerical models, or if you really want to use a language model, you can try to hybridize with code execution and careful prompting on your own risks.
PS here: I tried my hardest to spare you of the data science lingo from these papers that even NotebookLM couldn’t “optimize” for (thanks to my reader Jake that told me to try not to use so many acronyms.)
LLMs didn’t kill rigor. We did.
So, no, AI for data analysis doesn’t “suck”, it’s just that somewhere along the way, data work stopped being about understanding and became about output speed. Push a prompt. Get a chart. Move on. And that mindset is now flowing into every layer of analytics, from product teams to executive dashboards.
You don’t need another blog post explaining why LLMs struggle with numbers. You need leadership that understands why you can’t skip validation. You need infrastructure that treats data like something worth verifying.
We’ve trained ourselves to expect validation instantly: autocorrect, autocomplete, autogen. Now we want the same thing from models that were never built to replace rigor. And so we cut corners, skip the math and end up sacrificing structure and precision for speed.
Meanwhile, the foundations like machine learning, deep learning, and statistics are still sitting there ignored, even if they are proven and battle tested time after time again. But that happens because they take time, they make you think and they don’t give you dopamine on demand.
If you want to actually work with AI, not just act like you do, you need to go backwards. 200 steps if necessary. Learn the mechanics, the math and why certain models exist and what they’re built to do.
LLMs didn’t kill rigor. We did. By pretending inference is insight, and that convenience is a substitute for understanding.
Until next time,
x
Juliana
Sure, everything in this article is true, but the whole premise is wrong. Throwing giant reams of data and numbers at them and ever expecting sense from the prediction is madness.
They are great at writing code however, and that code can be used to do the analysis. Most of the AI services we have now like Cursor, Claude code etc, have tool usage or MCP access so they can do more than predict text. With access to extra tools and chain-of-thought reasoning, there is emergent behaviour beyond the "stochastic parrot" which looks and smells a lot like understanding.
With an MCP to Google Sheets, the LLM can write the cell formula, or the appscript to prepare the data. With an MCP to a database, it can write the SQL, it can write the python and pandas analysis, it can write the jupyter notebook, or create the streamlit ior observable or other interactive data-viz story for you. It won't ever do the data analysis directly, but all of this coordination is going to end up behind the scenes so for the regular user, it's going to look exactly like it's the LLM doing it. Nevermind it's an API with some decision systems and routing to RAG and a bunch of tools. The end user doesn't care.
It's the same with how amazing the latest OpenAI models are with images. It's not because the transformer or diffusion model suddenly got so much better, it's because it has access to photoshop-like tools. Crop, frame, remove background, scale, rotate, colour, skew. These are all just regular software tools that when orchestrated by the AI and strung together are effectively one system. The fact that you know there's transformer architecture and text prediction going on is besides the point. It's now one small cog in the wheel. Pretty world-changing cog, but just one, and one of very many.